



- 🗒️File Info
- 📋转载日期: 2024-09-14 19:01:42
- 🔗原文链接: 该如何学习 R 语言?
- 📑原文标题: 该如何学习 R 语言?
- 🤵作者: zhihu.com
- 🏡源站: www.zhihu.com
- 📃简介: 背景金融小硕,想学习R语言却不知道应该如何学习,应该按何种步骤,看哪些书或者视频资料等东西,所以提…
本文由 10k 使用 简悦 SimpRead 转码, 原文地址: 该如何学习 R 语言?
10k的话-写在前面
本文主要剪藏于知乎,建议从字数少的(第五篇)开始食用,纸质书结合视频课程同步学习。
具体个人学习经历和体验持续更新中
第一篇

黄耀鹏
今年年初开始接触 R 语言,自学兼修课,学了一个学期,暑期在某上市互联网公司找了一份纯粹用 R 语言工作的的数据分析实习,现在应该可以说熟练掌握 R 语言了。我的学习路径如下:
- 名师指导——学习 coursera 公开课;
- 巨人肩膀——浏览技术博客 + 几本入门书籍;
- 社区帮助——很多牛人只是比你更善用搜索引擎;
- 三人行——找到一个一起学习的小伙伴;
- 实践实践实践——用 R 完成 Assignments,做助研,找一份数据分析实习。
一. 公开课推荐。
公开课首推 http://coursera.Org 上约翰. 霍普金大学的数据科学系列课程。该系列完全使用 R 作为分析工具,轻松引领你从 R 的初学者转变为 R 的开发者。
该系列课程包含如下几门课。
1.《数据科学家的工具箱》
该课程主要介绍了数据科学家常用的一些工具。包括 R、 RStudio、 Git 、Github ,这里强烈推荐 RStudio,作为 R 的一个集成开发环境(IDE), 它可以在 Latex、 PDF、 markdown、 html 中游刃有余,并且是个强大的 Literate Programming 工具。除了以上提及的强大工具之外,还介绍了数据的类型、数据分析的方法过程、以及数据科学的一些知识点。
2.《R 语言程序开发》
主要内容包括:1)R 概述,R 的数据类型和对象,数据的读写操作;2)R 中的控制流,函数式编程,作用域,时间数据类型;3)循环函数,检查代码漏洞的方法;4)数据模拟实现,代码风格规范。
3.《获取和整理数据》
完成这门课程将获得技能:1)从各种资源获取数据;2)数据清洗的原则;3)数据整理的工具与技巧。
4.《探索性数据分析》
完成这门课程将收获:1)运用 R 中的 base,lattice,ggplot2 等绘图系统进行数据的可视化展示;2)对不用类型的数据运用基本的数据展示原则创造丰富多样的分析图;3)基于特定问题出发,运用探索高维数据的统计技巧,创造多维度数据的可视化方式。
5.《可重复性研究》
通过这门课程,你将学会:1)使用 Rmarkdown 撰写文档;2)在分析报告中嵌入 R 代码;3)用 knitr 等相关工具编译 Rmarkdown 文档;4)进行可重复性的数据分析研究。
6.《统计推断》
这门课主要介绍统计推断的基础。可以收获:1)统计推断的概览;2)进行统计推断的模型假设;3)复杂统计推断的技巧。
7.《回归模型》
这门课教会学生:1)如何进行拟合线性模型,如何进行残差分析;2)进一步探索如何引入哑变量解决特殊的模型设定问题;3)介绍广义线性模型,特别是 Poisson 回归和 Logistic 回归。
8.《实用机器学习》
完成这门课将收获:1)经典机器学习算法;2)如何应用多种机器学习工具;3)如何对真实数据进行模型评估和预测。
9.《数据产品开发》
内容涵盖:1)如何创造统计产品以进行交互式探究;2)重点学习如何探究不确定性的统计结果;3)如何创造 Shiny 应用,以及数据产品相关的 R 扩展包。
二. 技术博客和书籍推荐
-
R-bloggers:R-bloggers | R news and tutorials contributed by (573) R bloggers
-
R and Data Mining: http://www.rdatamining.com/
-
肖凯老师的个人博客:http://xccds1977.blogspot.com/,肖凯老师推荐了十几本 R 参考书。
-
书籍:《R 语言实战》,《R 语言编程艺术》,《机器学习——实用案例解析》,《ggplot2 数据分析与图形艺术》,这些书都有中文版。
三. 社区帮助
l R 自带的帮助文档;
l R Journal: Welcome. The R Journal,对研究某个包非常有帮助;
l 一个神奇的网站:http://Stackoverflow.com,牛人聚集,99.9% 的 R 问题都可以在上面找到你想要的答案;
l R Mailing List: https://stat.ethz.ch/mailman/listinfo/r-help;
l Talk Stats: Statistics Help @ Talk Stats Forum;
l Google,善用英文搜索;
四. 小伙伴
找到一个志同道合的同学一块学习,一块在 coursera 上刷 Assignments,互相帮助检查代码,互相督促看书敲实例代码进度,比较容易坚持下去,在此,感谢 hetal 链。
五. 实践实践实践
我在学校选修了两门 R 数据分析相关的课程,并且给老师做研究助理,用 R 完成老师布置的编程任务,学以致用,非常高效率。暑期的时候找了一份数据分析实习,实践两个月,对代码的规范化和可重用性的重要性有了更深刻的理解。
更新:
最近才刚开始在知乎答题,没想到会有这么多的人点赞,真的非常感谢大家的认同。评论区有的同学反馈了几个问题,在这里罗列并补充说明一下。
- 公开课很 boring,你居然刷完了?
- 没有统计学基础,可以按这个路径学习 R 吗?
- 刷个课就能找着数据分析实习?
对于问题 1,我非常认同,其实我也没有刷完整个系列。主要是因为进度太慢,内容太少,并且我是统计专业出身,课程的很多内容我已经有了一定的把握。但是,我认真的刷完了第 2 门和第 8 门,完成了相应的 Assignments。我相信这个系列课程对欠缺一定的统计学基础的同学一定会更有帮助。
对于问题 2,我的回答是 “definitely yes!”.
对于问题 3,我想这位同学应该没有仔细看完整个答案。我虽然是用一个学期从开始接触到掌握,但是花的时间也还挺多的。其中,花时间最多的时候是给老师做助研,研究一些 R 的新奇功能,以及一些 R 包源码。另外,我用 R 完成了四门课的小论文(报告)的编程。
突然想到在 Quara 上曾浏览到的一个回答:How is Hadley Wickham able to contribute so much to R, particularly in the form of packages? 有一定基础的同学我觉得是可以借鉴学习的。
Hadley 大神是这样回答的(我想谁是 Hadely 应该不用解释了吧 (●’◡’●)):
- Writing. I have worked really hard to build a solid writing habit - I try and write for 60-90 minutes every morning. It’s the first thing I do after I get out of bed. I think writing is really helpful to me for a few reasons. First, I often use my writing as a reference - I don’t program in C++ every day, so I’m constantly referring to @Rcpp every time I do. Writing also makes me aware of gaps in my knowledge and my tools, and filling in those gaps tends to make me more efficient at tackling new problems.
- Reading. I read a lot. I follow about 300 blogs, and keep a pretty close eye on the R tags on Twitter and Stack Overflow. I don’t read most things deeply - the majority of content I only briefly skim. But this wide exposure helps me keep up with changes in technology, interesting new programming languages, and what others are doing with data. It’s also helpful that if when you’re tackling a new problem you can recognise the basic name - then googling for it will suggest possible solutions. If youdon’t know the name of a problem, it’s very hard to research it.
- Chunking. Context-switching is expensive, so if I worked on many packages at the same time, I’d never get anything done. Instead, at any point in time, most of my packages are lying fallow, steadily accumulating issues and ideas for new feature. Once a critical mass has accumulated, I’ll spend a couple of days on the package.
- Finally, it’s hard to over-emphasise the impact that working full-time on R makes. Since I’ve left Rice, I now spend well over 90% of my work time thinking about and programming in R. This has a compounding effect because as I built better tools (cognitive and computational) it becomes even easier to build new tools. I can create a new package in seconds, and I have many techniques on-hand (in-brain) for solving new problems.
我觉得 R 的入门门槛是比较低的,即使你没有编程基础,只要你集中一段时间(几个月?)投入,你应该就能享受到它带给你的便利。但是,要想成为一个 R 开发者,是需要持续的付出一定的时间和精力的。
阳光男孩
其实相对于常见的编程语言,R 语言还是非常容易上手,并不需要很多年的编程经验。而且可以在数据分析领域大展身手。
第二篇
前言
我当初学习 R 的时候在网上搜到一则流传很广的 R 语言学习路线图 (
), 我在微信圈,微信公众平台上也见多次,写的确实很详细。但是对一些没有编程经验的童鞋来说,学习的难度还是太大了。后来自己浏览了很多 R 语言书籍,尝试了一些门槛比较低的书籍。自此,R 语言学习才走上正轨。以下涉及内容包括 R 语言书籍的推荐,以及 R 语言相关课程的推荐,学完这个教程的内容之后足以应付工作学习中遇到的统计分析的问题了。
经典书籍推荐
R 语言有两类书籍比较 “坑”,一类是 Programming 类,一般都带 programing 字眼,但不绝对。这类书籍一般是计算机背景的人写的,关注的重点是编程(鞋代码和编程不是一码事),底层的运行机制之类的,比较难以捉摸,典型的例子是《The art of R programming》。还有一类是讲统计知识比较多,而且喜欢推公式。虽然有所裨益,但是会分散很多学习 R 的精力,可以作为后期提高的书籍,但是作为入门不太合适, 像《The R book》。
讲完了 “不好的”R 的学习资料,可以规避一些“误入歧途” 的风险。下面介绍一下我觉得比价有用的学习资料。学习任何语言的捷径就是 Learn by dirty。这里推荐一个网站,code school 的 Try R 课程,非常基础,从最基本的语句的赋值到最后的数据框的基本操作,手把手一步一步的教你,然后对你输入的语句,网页会给出判断,如果写错了,还有很详细的解释。网页全部是英文的,英语过了四级的童鞋应该可以应付了。
R 的入门书籍,比较好的是 Learning R , 中文名是**《学习 R》**。第一章到第五章的数据的基本入门,必须要细看的,而且要读好几遍的,这是 R 的最基本的东西,需熟练掌握,多家练习。别觉得看懂就行了,只有自己敲出来运行正确才行。第六章环境和函数这一章建议直接跳过,比较抽象,等回头 R 学的差不多了,再回头看比较好。大多数人,平时基本不涉及到这一样的内容。第七章 字符串和因子也是很重要的一章,特别是医学领域。第八、九章的循环,量力而行。第八章的内容其实大多数其他编程语言都会涉及。但是在 R 里面,这些显循环,用的较少。其实主要还是向量化的操作为主,也称隐循环。第九章的隐循环非常有用,是 R 最精华的东西,就是学习起来有点困难。其主要内容是 apply 族函数,包括 lapply, sapply, tapply, apply, mapply 等。这本书最优秀的地方在于数据的 subset 部分,各种方法讲的非常详细,也有很多的例子。这也是 R 语言比较难入门的地方。
《R in Action》 确实一本非常优秀的书籍,我看喝多大神都推荐这么书,我大概学了一遍,确实非常不错。这本书非常好的地方在于围绕具体的问题展开,教你如何利用 R 进行操作,而且选取的例子也非常具有代表性,所以建议每个例子都要详细研究。但是这本书学习曲线比较陡峭,可能上一章的内容还没有消化,又要开始新的内容了。遇到问题时建议多点耐心,谷歌或者请教别人,把这些知识点掌握了,这是 R 的基础。
还有一本书,《R cookbook》,这本书是围绕具体的问题进行设置的。所以可以作为一个遇到困难时候的快速翻阅手册,里面特别有用的章节是如何运用 apply 组函数,上面两本书都讲得不是很详细。
R 绘制统计图的功能非常强悍
(你见过这么令人心神荡漾的图嘛!)
你见过的没见过,想到的,没想到的,都可以绘制出来哦。哈哈,心动不如行动,几行代码一敲,令人心神荡漾的图片就出来啦。R 绘图非常简单的,就是一个简单的学习记忆的过程。R 语言绘图发展的非常快现在有三大绘图系统,基础绘图系统,Lattice 绘图系统,ggplot2 绘图系统。虽然各有其使用价值,但个人推荐 ggplot2 绘图系统以及基础绘图系统。 Lattice 对于多分组的数据的展现比较好,但是 ggplot2 是可以很大程度上替代其功能,不学习也可以,非要用的时候依葫芦画瓢就可以了。
下面主要介绍 R 的基础绘图系统和 ggplot2 绘图系统的学习路线。R 基础绘图系统《R in Action》中,花了很大的篇幅介绍了基础绘图系统,如果学习完了,工作中碰到的很多统计图就可以胜任了。如果你喜欢钻研,可以看看谢益辉(Knitr 包的作者)的**《现代统计图形》,讲的非常详细和透彻。不仅如此,更是讲解了图形的选择,图形的设计方面的知识。学有余力,不妨学习一下 ggplot2 绘图系统, 推荐《R graphics cookbook》**一书。书中不仅有 ggplot2 的绘图代码而且还将其与基础绘图系统进行了比较。介绍的图形非常实用,而且 ggplot2 的扩展性非常强,可以发挥你的想象力,创造一些新奇的图形。

(R 语言书籍全家福)
R 语言学习网络课程推荐:
- Datacamp,learn by coding 类型的网站,课程设置非常用心,难度合适,内容丰富,最好的 R 语言学习网站之一。

- 国内的视频课程
国内的 R 语言网络课程最丰富的应该是炼数成金(dataguru)平台,课程包括《R 语言数据分析、展现与实例》,《R 七种武器之交互化展示包 shiny》,《R 七种武器之文本挖掘包 tm》,《R 七种武器之数据可视化包 ggplot2》、《R 七种武器之数据加工厂 plyr》、《R 七种武器之金融数据分析 quantmod》、《R 七种武器之网络爬虫 RCurl(第四期)》等。其中比较适合入门的课程是
《R 语言数据分析、展现与实例》
- MOOC 课程
Coursera John Hopkins 专题课程不错 (已经上完 6 门课,2 门课正在学习中);还有 edX 上 MIT 的 The Analytic Edge 课程也不错。其他答案有详细介绍不赘述了。

4. 强烈推荐 Swirl 包,你值得拥有。
Swirl 包开发者毕业后就去了麦肯锡咨询公司了。
第三篇

任坤
=== 迟来的更新 ===
2016 年底我在 Packt 出版了《Learning R Programming》一书,内容包含了初级到高级的许多主题。厦大 WISER Club 的小伙伴们进行了翻译工作今年将由人民邮电出版社出版,几位 GitHub 上认识的日本朋友也翻译成了日语,年底或明年出版日文版。
下面是中文版的推荐语:
我毕业后一直在量化投资的一线工作,每天大量时间都是以 R 语言为主要工具研究金融数据,期间也在 GitHub 上开发和维护几个 R 扩展包,每年也参加几场 R 语言会议。在这个过程中,我接触了不少还在学校的初学者,或者已经步入数据相关工作的研究人员,也有一些发来邮件寻求帮助的世界各地的用户。我有这样一种感觉,我们的同学、数据研究者经常有丰富的想法,但原始数据的形式与这些想法常常有相当的距离。许多用户是因为对工具和编程本身不够熟悉而难以自由地操作数据,因而在面对稍显复杂的问题时便止步不前。如果是这样的原因放慢了我们探索数据世界的脚步,岂不是太可惜了?于是,我萌生了一个想法,写一本关于 R 语言编程的书。2015 年 10 月,Packt 出版社的编辑邀请我写一本面向初学者和专业用户的 R 语言书籍,这正合我的想法!经过 1 年的时间,便有了这本书。
这本书与其他 R 语言书籍有一个重要的不同:该书更倾向于帮助读者系统化地认识 R 作为一门编程语言的设计和行为,通过许多例子和实验帮助读者弄清楚 R 语言中各种常用数据结构的行为,以及所有这些行为背后统一的设计原则和行为准则。对于许多初学者以及其他编程语言的用户,R 语言是难以预料、充满怪癖的,至少不是十全十美的。但是,当了解到这些统一的行为准则时,你可能会惊叹 R 语言本身的一致性,以及表达数据和逻辑的灵活性。这些特性允许我们高效地进行数据探索、分析、可视化、报告等等。本书将用一半的篇幅来介绍基本的 R 语言和对象,然后步入 R 语言的高级特性,让读者更加深入地理解其行为,形成一个全景图。此时,当你写出一个 R 语言表达式,你就能立刻猜想会发生什么,即使和想象的不一样,也能很快找到问题所在。打好了这个基础后,我们会介绍数据相关的主要技术,包括关系型与非关系型数据库,实现快速数据操作的扩展包等等。掌握了语言和对象的特性以及流行的扩展工具后,我们就可以随时根据问题选择我们的工具,因而生产力就能大幅提升,将主要经历投入在思考和解决业务问题,而非一知半解、绞尽脑汁地去找代码中的纰漏而摸不着头脑。最后,本书介绍了一系列工具,涵盖数据研究的多个方面,读者可以根据自己的需要继续学习。
本书原版为英文版,对于国内的读者可能阅读中文版更加方便。为了保证翻译的质量,我推荐厦门大学王亚南经济研究院(WISE)的研究生学弟、学妹们翻译此书。他们来自于一个自发组织的数据科学小组 WISER Club,经受过严格的学术训练,参与过多种数据研究项目,对 R 语言相关的应用已经有相当的经验,并且对推广数据科学充满热情。
希望这本书能让你更加深入地了解 R 语言和相关工具,更加自信、自由地探索数据的海洋。
学习 R 比较有效的过程
由于 R 语言主要是和统计、计量、数据挖掘等领域相互联系,因此核心是这些领域中的问题,R 的任务就是帮助你花更多的精力在思考和解决这些问题,而不是做计算上或者技术上的底层架构,或者不断重造轮子,并且不丧失灵活性(可编程性)。因此,学习 R 可能并不像学习纯粹的一门编程语言一样,最好需要在这些问题的上下文中学习,脱离了数据科学的背景学习 R,仿佛就是学习如何使用扳手,却根本不认识螺丝钉。
根据我自己的经验,学习 R 比较有效的过程基本上是:
- 看在线互动教程、打代码,了解 R 的最基本的东西,大概能做哪些事情(比如计算一些线性回归),自己根据这些教程去做各种变化,做许多实验,探索一下这个语言的基本语法和构造。
- 看一些入门书籍,比如 Introductory Time Series with R 等等,给你展示怎样用 R 来比较完整地解决一个问题。可以根据你的领域选择类似的书籍。
- 开始用 R 解决一些统计、计量相关的计算性问题,比如用自己的数据跑一些模型,探索这些数据里面可能有趣的东西。
- 在数据较为复杂一些的项目中使用 R,发现数据操作能力太弱,开始接触更深层的 R 概念,比如可以看 Data Manipulation With R (Phil Spector),形成更加系统的概念,逐渐掌握操作复杂一些的数据和对象的能力。
- 学习最流行的 R 扩展包的使用方法,发现整理数据和建模中的许多工作都大幅简化,工作效率出现质的提升。
- 逐渐开始做更为复杂的项目,形成一整套数据处理、建模的技术和技巧,形成较为系统、完整的认识和知识结构,有较强的社区检索能力,遇到问题能够自行解决或者通过社区解决。
- 阅读进阶的书籍,例如 Hadley 的 Advanced R Programming,对 R 的底层和开发有了更加深刻和全面的认识,形成了使用 R 的基本直觉。
- 参与到开源社区,不断跟进最新的发展和技术。
- 参与到 R 会议,结交更多的朋友,交流使用经验,进一步提升视野和能力。
R语言书籍
R 语言有很多国外的书籍,建议就你的研究领域或者工作领域来选择书籍。
假如你做的是时间序列分析,那么作为入门你就可以看《Introductory Time Series with R》,里面有很多生动的例子,数据也可以直接获取。把书里的例子和练习都做掉,每个例子用自己的数据去多做些实验,自己探索一下涉及到的函数还能做些别的什么,并且看看这些函数的文档。
此时对 R 已经有了初步的了解。如果做到一定程度,开始用于自己的项目,就会发现自己用 R 处理数据的能力很弱,一般表现为想把一种数据处理成另外一种样子,但是不知道如何实现。此时,需要补充一下用 R 整数据的基本方法,可以读《Data Manipulation With R - Phil Spector》,里面通俗易懂地介绍了 R 数据处理的基本观念和方法,让你大概知道 R 处理数据时是什么样的机制。这样你在写代码时就有更高的预见性,否则很容易出错。
接下来需要比较系统的应用,这就需要你把 R 作为主要的生产语言来完成你的项目,在此之前如果为了练手,如果你是研究者那么你应该找几篇你的研究领域的论文并用 R 复制出来,再次过程中你会修补很多缺漏和不熟悉的地方,也会对数据处理和分析建立起一些直觉。
之后就是不断地积累了。
(PS: 建议使用 RStudio 来做 R 开发,目前的 Release Preview 版本有了不错的调试能力,严重推荐)
最近的一篇英文文章谈了这个:Kun Ren - R: Getting Started
2014-03-17 资源更新
最近密集地用 R 做较为复杂一点的金融交易相关的项目,有很多资源值得大力推荐。
首先,如果想从 R user 成长为 R programmer,要走了路还是很长的,这不仅涉及到了 R 的基本应用,还涉及到用 R 语言作为主要语言开发较为复杂一点的项目。如果项目开发涉及到团队合作,并且希望项目能够实现代码重复利用、使用灵活、提升代码的运行效率、加快产品开发周期等等,那就不简单是学习 R 的问题了,还有许多工具需要使用,下面列出一些需要掌握的东西:
-
版本控制系统 Git,面向团队开发可以将项目托管在 GitHub 或者 Bitbucket 㩐网站上
-
一些编程本身方面的技能,例如函数式编程等等
-
充分利用已有的成熟扩展包做一些较为复杂的数据操作和可视化,例如 plyr 做 data.frame 拆分——变换——整合, reshape2 做 long format 和 short format 数据表之间的转换, data.table, lubridate, stringr, ggplot2 等等
-
掌握一定的数据库使用方法,例如用 RSQLite 扩展包操作简单易用的 SQLite 数据库
-
程序调试(debugging),能够找到程序不完善的或者有错误的地方和比较根本地解决错误根源
-
遇到问题能快速自己解决,解决不了或者认为解决方案不太好能够在 stackoverflow 上发现解决方案或者提出问题
根据 Hadley Wickham 的说法,R 目前面临的一个主要挑战就是 R 的主要用户群都是业余使用者(R user),而不是专业开发人员(R programmer),这两者写出的项目从质量到运行效率、可扩展性、可重复性、开发周期、共享度都天差地别。如果希望自己的项目实现上述特性,你自己或者自己的团队必须能够升级到 R programmer 的水平,一个要旨就是大量的使用、参与社区讨论,有问题多自己解决或者在社区寻求帮助,发现扩展包的问题直接去 github 或者其他社区提出 issue 或者直接 fork 项目提交改进方案。虽然使用 R 的人群中大部分不是专业的 IT 从业人员,而是研究者、金融领域相关人员,但是提升自己的技能到专业水平有诸多益处。有一定经验的使用者,建议读一下 Hadley Wickham 的 Welcome · Advanced R. 里面的全部文章,内有许多很有价值的东西,值得花时间思考的学习。
另外,我的博客(Kun Ren - Blog Posts)也在缓慢更新自己使用 R 的一些心得。
2014-04-12 更新 Github-LearnR
我在 GitHub 上写的一个帮助学习 R 的开源项目 learnR (renkun-ken/learnR @ GitHub)最近一个月增加了大量内容,从初级到高级、常用扩展包、数据可视化等等。R 最强大的地方是扩展包,例如 stringr, reshape2, plyr, dplyr 等等用来做数据操作速度很快很好用,比起 R base 提供的函数要方便得多,因此掌握一些流行的扩展包是非常有必要的。
最近做了一个模仿 F# pipeline operator 的 R 扩展包 pipeR(renkun-ken/pipeR @ GitHub),可以大幅简化流程化的数据操作,欢迎使用!
=== 2014-07-06 更新 ===
最近发布了一个新的扩展包 rlist
Editor: rlist:基于 list 在 R 中处理非关系型数据
第四篇
钱粮胡同

有更新。已经不少答案了,市面上的书也基本说齐了,我就谈谈我自己学习 R 语言的经历吧,也许对于大部分零基础的同学来说会有一定参考价值。同时看到问题也有金融的标签,题主也有金融背景,挺合适~
说来惭愧,我是直到工作才接触的 R 语言。编程基础有一些,本科那会儿是 EE,学过 C,用过 matlab,但是相隔时间太长,后来出国换了专业,那点儿 coding 的能力基本还回去了。读博后用的软件更少,主打是 stata,偶尔写个 vba 处理点数据,仅此。现在想想,当时如果用 R,很多数据的处理要轻松太多。
工作后,金融机构里 Excel 的使用频率还是很高的。然而,工作原因,很多时候接触的数据量巨大,就算没超过 Excel 的限制(下图),用起来仍然很痛苦 - 当时的想法就是,再不换个工具,公司就该把我换了。同事推荐了 R,也就是那时开始,硬着头皮,开始了不懂装懂,自学 R 的阶段。
Excel 的一些局限性:

说到这里,我觉得需要先弄清一件事儿,R 到底有什么用?
看到很多答案都说到 R 离不开统计,用 R 来建各种模型做复杂的分析等等。说的没错,R 的诞生注定了它这辈子离不开统计的根儿,但是 “小白” 的说一句,R 的用途,哪怕仅仅光是数据处理这一块,就已经足够理由来学习。也因此,我个人觉得 R 的用途可以划分成两块:
- 数据的处理与 “腾挪”(data manipulation):具体用途如高频率重复性数据处理工作,相对自动化的基础分析与 reporting - 致力于纯粹生产率的提高;
- 算法与模型:R 有很多 package(包)可以装(把它想成一个软件需要配一些 plug-in),使得在 R 里面直接应用各类模型变得异常简单(这是好也是坏) - 小到做个毕业论文或者业余爱好分析些数据,来个回归耍个自然语义分析再也不是遥不可及的事情,大到像德意志银行的各类企业与金融机构内部评级模型等都在用。
那么,看清楚了 R 的两个用途,就可以想想自己从哪个角度入门 R 语言比较合适:
- 如果你本身没有很好的统计背景,工作也不需要很多这类复杂金融模型或算法,你可以选择数据操作这个角度来学 R - 这个方向我感觉每个人都适合,不需要学术或理工背景,更别提所谓金融背景了 -> 我认识一个 DB 同事,文科背景,数学除了加减法其他基本还给老师了,学 vba 一年多基本还是文盲水平,接触 R 语言 6 个月,运行一些实用的批量数据处理与 reporting 6 的飞起~;
- 如果你有算法或模型分析的需求(或者有一定的数理 / 编程背景),那啥都别说了,算法与模型这块肯定要搞(但是学的更多的是如何用 R 来实现你的模型和想法)。然而即使是这样,数据的处理与腾挪在平时的日常生活中也是非常实用且常见的(后面给个例子),应该熟练掌握。
至此,如果还在考虑是否适合学习 R 语言,不如先给自己打点儿信心:用 R 不代表就是高大上,不要上来被很多人说的统计计量,算法建模什么的吓跑了。个人愚见:如果能用 R 做好大量数据的快速处理与基础的分析,这本身就是一个很好的技能。毕竟,在金融机构,不是每个人都需要成为一个 quant,基础性工作 R 完全可以胜任,甚至做得更好 - 当你旁边的同事还在痛苦 Excel 打开一个大数据文件龟速的时候,你的报告已经做完了,区别就是这么明显~
话说回来,我最开始接触 R 是因为需要做一个 portfolio 的分析,数据量比较大,当时用 Excel 搞不定,打开文件,慢,直到能用的时候基本快下班了。迫不得已,用上了 R。我自己觉得,学 R 最好的途径就是直接上手,实现的过程中有不懂就直接 google,基本上大部分的讨论都会指向 stackoverflow 这个网站,唯一注意的就是搜索问题的时候,如果条件允许,尽量用英文搜,关键词尽量选的精炼 - 英文不好的话权当练英文吧。
当然,这种方法有点儿江湖野路子的感觉,有可能一开始 google 两下,左抄抄右抄抄拼出了一个程序,run 了一下,高兴的不得了,副作用是养下了比较差的 coding 习惯,对 R 没有一个系统性的认知。弥补的方法是在这个期间同时看一两本书,不要多,要精。我总共看的 R 书就不多,好推荐。入门的话我只看过:
- Learning R (中文版好像就叫学习 R,中亚平装 58 元左右):这本书前半部分讲 R 的基础,可以做参考用;后半部分着重讲如何做数据分析,以及分析的整体流程,这个比较有意思,推荐买一本阅读。
其他几本多少碰过的:
- R Programming for Data Science
- R for beginners
- R Cookbook
- R in Action (或 Quick-R 网站)
- ggplot2:数据分析与图形艺术
- Discovering Statistics Using R
这几本都不错,有些网上有免费公开的 pdf,如:R for beginners 中文版。然而,我都没读完,但是我觉得这并不影响学习 R 的过程:当你硬着头皮,实践加摸索做了几个 R 的项目的时候,一方面积累了一定的信心和兴趣,另一方面如果过程中有问题再去翻翻这些书也会更有感觉,这是个相辅相成的过程。
如果是有一点编程基础,或者懂一点点 vba 的同学,其实完全可以搞一本 R 的手册放手边随时参考就好,比如 O’REILLY 出版的《R 语言 - 核心技术手册》,或是大部头《The R Book》,当然,为了熟悉 R 的大概特性,也可以抽时间快速的在网上学院过一遍免费互动课程,我当时用的是 Codecademy 的 R 免费互动教程,链接:R Programming Tutorial | Code School ,也可以去 codeschool 学习那里的互动教程(不用麻烦的注册),移步:Try R ,如下图:
说回那个 portfolio 分析的案例,我当时需要把几十万个公司的名字预处理一下,也就是如果公司的名字里包含比如 Inc,或者 corp,或 oyj,或 plc,或 holdings 等等这类比较常见的字段,我需要删掉它,为之后的分析做准备。由于数据量较大,同时这个步骤每隔一个月就要做一次,属于相对重复性的一个基础数据处理过程,我感觉这种场合用 R 比较合适,远胜于其他软件的处理方法(如果有的话)。
举例:想要删掉整个数据库中任何公司名字中 “corp” 这个字段的话,我只需要一行 R code:
database$groupname <- gsub(" Corp$","", database$groupname)
不需要任何循环语句,R 一句话就可以解决这个问题。想想以后拿到数据,运行这一句就可以处理掉几十万公司名字里 Corp 这个字段,生产率势必提高,同时也防止了任何可能的类 Excel 人工错误等。说实话,当时就这一行 R 代码,让我窥到了 R 的冰山一角,顿下决心要把 R 拿下。
这种简单的数据处理一点儿不高大上,然而在平时工作中遇到的频率却很高。做过研究的同学肯定有感,run 一个模型往往不需要太多的时间,更多是去解释结果,而最费时间的很多时候往往是数据的获取与预处理。之前所说,R 在数据的基础处理方面有着很强的优势,花时间学习一下,即给以后如果要学习模型或算法打下一个坚实的基础(入门),同时也可以学了就用 - 既装了 X,又可以大幅节省数据处理的时间,最小化人工错误等,何乐而不为。
Portfolio 分析这个项目做完后,我也意识到了 R 的优越性,兴趣起来了,逐步入门,在之后的工作中时刻留意经手的项目,合适的情况下尽量用 R 来完成。当然,这并不是说什么都应该用 R,有些问题明明很好解决,Excel 足够了,这种情况下没必要为了用 R 而用 R。
如果手头一时想不到什么现成的项目也没有关系,找一本不错的参考书,跟着里面一点点的代码打一遍用于理解;或者也可以去 Kaggle 这类型的网站,里面有很多竞赛案例,提供了详细的项目介绍以及配套的 R 代码等,一步步带你入门,链接如下:
Kaggle 泰坦尼克号数据分析项目:Titanic: Machine Learning from Disaster - 数据分析与机器学习,挖掘信息 -> 泰坦尼克号上什么样的乘客最有可能被救?这个项目同时提供如何用 Excel 和 Python 来分析同样的问题,让你对这几个工具的分析逻辑有一个切身的对比。
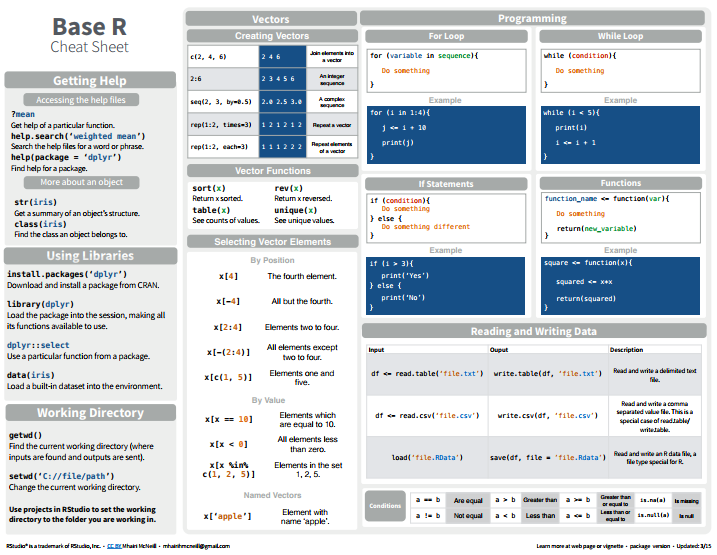
最后,在学习 R 的过程中,可以把 R 的一些 cheat sheet 打印出来放在手边,随查随用,非常方便有效,比如 R 的常用命令 cheat sheet:
- Data wrangling 的:https://www.rstudio.com/wp-content/uploads/2015/02/data-wrangling-cheatsheet.pdf
- RStudio IDE 的:https://www.rstudio.com/wp-content/uploads/2016/01/rstudio-IDE-cheatsheet.pdf
- R reference card: https://cran.r-project.org/doc/contrib/Short-refcard.pdf
后话:
工作之余,我在法兰克福这边开了一门课,讲的是 R 的入门以及如何用 R 做组合分析,简单补充一点儿放这里,供大家参考:
- 第一堂课是简单介绍 R 的历史,特点以及带着学生把 R 的环境装好(R 的 core 文件以及 R Studio),这里下载:The Comprehensive R Archive Network 和 RStudio
- 第二节课就是给大家一个 R 文件,里面是所有 R 的基本语法,一个个挨着运行,亲身找找感觉(我觉得这类工具最好的学习体验就是上手打代码)。配合 R 的注释功能,熟悉 R 的各种基本运算和变量类型等,这本身就是实用且互动的教材。有兴趣的朋友可以按照这个方法自己写一个 R 的文件,类似下面这个:
#Assignments
x = 1/3 #result assigned to a variable
x <- 1/3 #alternative way to do assignment
1/3 -> x #yet another way (not recommended)
assign("x", 1/3) #and one more :)
x1 = x2 = 0.3 #multiple assignments in one row (from right to left)
.Last.value*2 #access last value used (not recommended)
ls() #shows all variables
ls.str() #shows variables and their values
rm(y) #removes variable
rm(list=ls()) #removes all variables
#Variable Types
a=1 #numeric
b="aaa" #integer
c=FALSE #logical
d = as.integer(1) #integer
e = 1 + 2i #complex
#Display variable type
class(a)
class(b)
class(c)
class(d)
class(e)
class(sqrt) #functions are simply variables of type function
...等等
#有兴趣的同学可以按照这个方法一点点补全这个基础文件。选本参考书,按照书中基础部分的
代码,一点点系统性的写到这里(配合注释#),在R中直接运行,互动性的学习。
- 第三节课学习一些 R 常用包,投资方面的话顺便介绍一下 quantmod 这个包,以及如何用这个包来下载股票数据做分析等(下面例子里都是德国 DAX 的公司):
if(!require("quantmod")) {install.packages("quantmod"); require("quantmod")}
TickersDAX=c("ADS.DE", "ALV.DE", "BAS.DE", "BAYN.DE", "BEI.DE", "BMW.DE", "CBK.DE", "CON.DE", "DAI.DE",
"DB1.DE", "DBK.DE", "DPW.DE", "DTE.DE", "EOAN.DE", "FME.DE", "FRE.DE", "HEI.DE", "HEN3.DE",
"IFX.DE", "LHA.DE", "LIN.DE", "MRK.DE", "MUV2.DE", "PSM.DE", "RWE.DE", "SAP.DE", "SIE.F",
"TKA.DE", "VOW3.F", "^GDAXI")
NamesDAX = c( "Adidas", "Allianz", "BASF", "Bayer", "Beiersdorf", "Bayerische", "Commerzbank", "Continental",
"Daimler", "Deutsche Boerse", "Deutsche Bank", "Deutsche Post", "Deutsche Telekom", "E.ON",
"Fresenius Medical", "Fresenius SE", "HeidelbergCement", "Henkel", "Infineon Technologies",
"Lufthansa", "Linde", "Merck", "Muenchener Rueck", "ProSiebenSat.1", "RWE", "SAP", "Siemens",
"ThyssenKrupp", "Volkswagen", "DAX Index")
DStart="2007-01-01"
DEnd="2016-12-30" #10 years of daily data
options("getSymbols.warning4.0"=FALSE) #disable too many warnings from getSymbols
options(warn=-1) #suppress too many warnings
getSymbols(TickersDAX, from=DStart, to=DEnd) #Download 30 securities from Yahoo Finance
...等等
- 第四节课就是介绍一些其他实用的 R 技巧或进阶工具,如:
- 如何用 R 实现字符串模糊匹配(fuzzy matching),可以用来为不同数据库中相同公司名字配对(很多情况下不同数据库中公司的名字可能有些许差异),且在某些情况下 Excel 的 vlookup 或 match 等并不适用,更别提 Excel 无法处理很大量的数据了。这里可以轻松借用 R 的一些包,比如 stringdist,稍加修改,直接调用包中的 Jaro-Winkler 或 Levenshtein 等模糊匹配算法,简单快捷(如果有同学有兴趣我可以把代码和大概的分析方法放上来);
- 如何用 R 实现快速灵活的投资组合压力测试等,如考虑宏观变量变化,企业评级迁移等。
- 之后的课程包括基于之前下载的 DAX 股票数据,将其应用到一些基础的金融模型里算算定价什么的,如 Black Scholes,Markowitz 等,也是借用 R 现成的一些包,如 quantmod, fOptions, fPortfolio, xts 等,这里就不详述了。
总之,我感觉从 R 入门到上手做出一些成果是比较快的。然而,一上来就想一口吃个胖子没必要,从入门到一个不错的 R 的应用者已经可以大幅提高你的生产率。至于 R 开发者或者算法大神,要量力而行 - 打实了基础,积累了信心与兴趣,一步步来。
第五篇

unstory
安装好 R、Rstudio
1、入门
推荐这个帖子,把里面的代码敲几遍,先对 R 有个基本的了解
看一下这个视频:
接下来学习 vector、list、dataframe、matrix,string、int、float、factor 这些数据结构、数据类型,学习控制流语句 (if for while repeat break)、apply 族函数,导入数据,导出数据,推荐 < R 语言实战 >,如果认真学完这本书,足够用 R 解决一些问题。不管你用什么学习资料,数据结构,数据类型,控制流语句是一定要学的。资料不用多,<R 语言实战 > 足矣。
2、用 R
入门以后,不要忘了你想用 R 做什么。如果是统计专业学生,推荐吴喜之老师的 <统计学 – 基于 R 语言> 课本,这本书上的例子和习题超多的,动手敲代码,动手做课后习题,敲完代码,肯定会对统计学有新的理解(统计图,假设检验、置信区间,p 值等),对 R 的操作也会更加熟练,接下来的统计课程,全都可以用 R。多元统计分析,推荐暨大王斌会老师的多元统计课本 (忘记叫什么名字了),时间序列分析,貌似潘虹宇的 <时间序列分析——基于 R 语言(第二版)> 很不错,不过因为我时间序列方面学的不怎样,学着学着有点迷糊,所以对这本书的评价一般。另外一本吴喜之老师写的 <时间序列分析> 应该也不错(没看过),吴喜之老师写的书通常例子习题多,较为容易理解。
其实只要学 R 语言快速入门~ 真的很快~_统计狂魔吧 、<R 语言实战>,剩下的用到再学,交给时间慢慢沉淀。学习是以需求驱动,解决问题为导向的,当然我们没有那么多需求,不会遇到那么多的问题,把 < R 语言实战 >、< 统计学 – 基于 R 语言 > 这两本书的例子敲一遍,习题自己做一遍,R 语言入门了!R 语言的帮助系统特别强大,以后想学什么,多看帮助文档。
这是我走了那么多弯路总结出来的办法,算是比较高效的。学一门语言,别人能帮的只有推荐资料,规划好学习路线,剩下的靠自己。
如果时间比较充裕,推荐这种学习方法。
评论区